The Engineering Emmy Technical Award Winning Plug-in
Dialogue is the lynch pin of film, television shows, documentary. If you can’t hear the dialogue, you loose the narrative flow, and the viewer is pulled out of the story and distracted. Sound is the single most important and influential technical factor governing viewer retention. It is very rare for a viewer to comment that they find the black levels too crushed, or that the grade is too green, or that the timing of the video edits is a bit hurried. Poor sound edits, compression or EQ, & mix levels (especially with respect to dialogue) are the single biggest source of complaint. For every 1 viewer that takes the time to write and complain, nearly 1000 simply switch the channel, as the BBC have found out to their chagrin more than a few times of late. So productions, when you budget your show, maybe spend a bit less time with “The Prince of Darkness” in his expensive colouring playpen, and a bit more in the sound edit and dub!
So with modern audio productions battling for our attention with ever more cinematic style; using sweeping musical score, foley, and overtly loud and dynamic fx, it becomes clear the job of dialogue mixing is becoming a taller order. However, help is at hand….
Veteran Academy Award-winning Hollywood Re-Recording Mixer, Mike Winkler has a uniquely successful blend of skills that he brings to the table in feature film mixes. Often film dialogue mixers have to push dialogue to help it cut through the score and FX mix. Boosting high frequencies and upper mid/HF is one of the starting points, but this can lead to harshness and sibilance if over done. To combat any harshness and sibilance, Mike had an engineer friend of his build a custom processor that he could insert in his dialogue buss during the final mix to catch any unwanted peaks. This processor was in danger of becoming fragile after many years of travel and abuse, so a software solution was required. Whilst working with Mike Minkler as a mix tech, Ceri Thomas suggested that the chaps at McDSP would be the perfect choice to carefully achieve this. So after much clever wizzadry by Colin and the boffins at McDSP, the SA-2 Dialogue Processor was born!
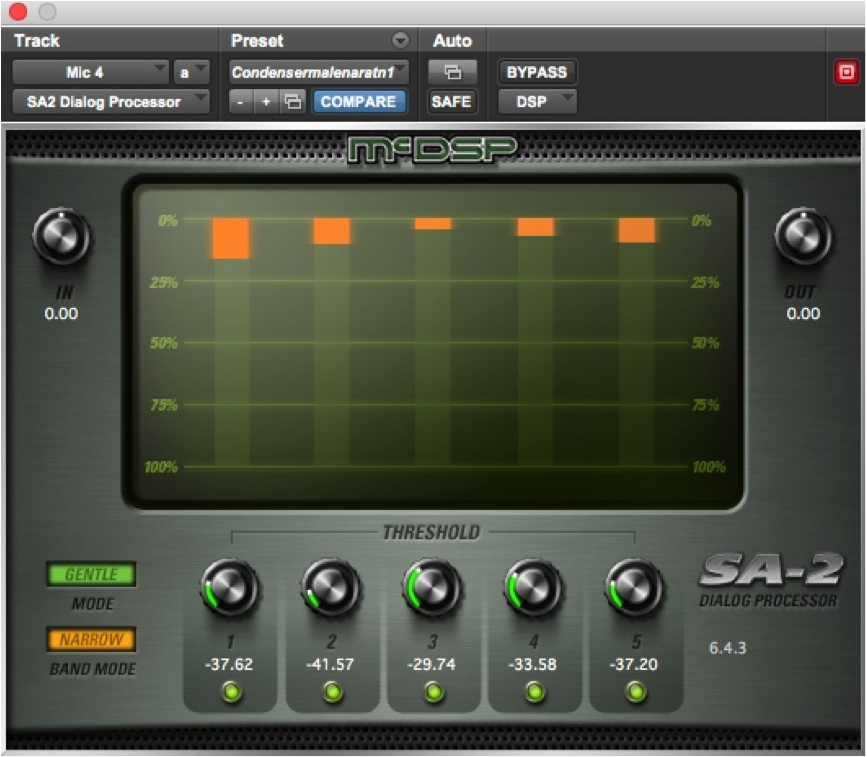
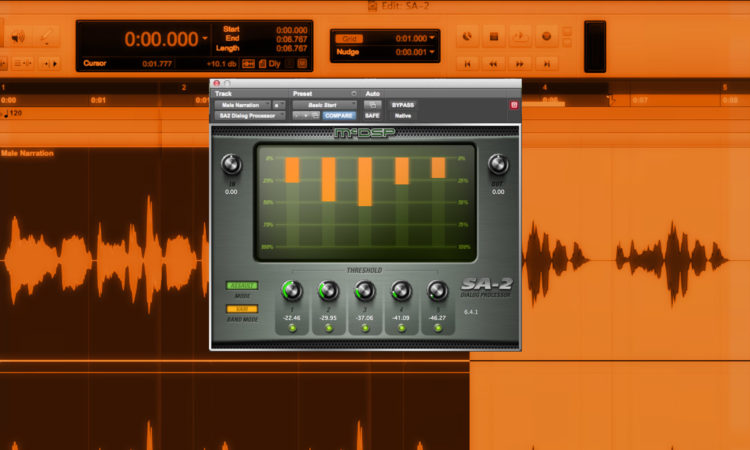
The SA-2 Dialog Processor is made up of 5 bands of strategic dynamic active equalization, chosen by Mike, with his vast experience, and is configurable in a variety of modes. Each band of active equalization has a threshold control to determine at what signal level the active equalizer begins to affect the signal. There are also green “enable buttons” for each band to quickly audition the effect of any given band (a band on and off switch).
There are two mode selectors:
- The MODE selector – for controlling the timebase ballistics of the active equalization (from gentle to severe)
- The BAND mode – a second selector for adjusting the width the five bands in the frequency spectrum (from narrow, via normal, to wide).
Finally, there are input and output gain controls for overall adjustment.
There are not many knobs, and not much else to see apart from the gain reduction meters. A relatively simple plug-in design that belies its power!
Being McDSP, it is available in AAX Native and AAX DSP formats. McDSP astutely know how vital for the film and TV post production world DSP plugs are, as we use them on AUX Inputs to avoid massive delay compensation issues with native processor round trips. This is something other software coders should please kindly note. The SA-2 is also available as AU and VST native flavours, for those of you who insist on using other DAWs.
To test what the chosen Minkler band frequencies were, I put some pink noise into the plug-in and spectrum analysed the output by turning on the various bands. The five bands are to be 3 KHz, 5 KHz, 7 KHz, 9 KHz and 11 KHz.
I inserted the SA-2 across the dialogue buss in a feature film mix (The Northern Paradigm) to check it out. The location dialogue for this film was very problematic, as it was shot in central London with a fast turnaround and a low budget (is it ever different?). I had to use considerable Cedar DNS One processing to salvage the dialogue, as there was no budget for ADR. The dialogue tracks had considerable LF and LMF EQ as well as Cedar processing to remove traffic and construction sounds, which can lead to slightly spikey and strident dialogue, as the frequency balance can now become uneven. Once I had dialed in a reasonable threshold, I tried the SA-2 on the Gentle (timebase) and Narrow (freq) settings with all bands active. Wow! Its not that often that a seasoned cynic like me has jaw hit the floor, but my dialogue all of a sudden had no “premix inconsistencies“ and any of my premix excesses were deftly handled indeed. The dialogue had a roundness and smoothness to it, it was more filmic and more ‘contained’! Nothing sounded out of place anymore.
I have also used this on documentary voice over recordings, where there were some broadband HF peaks – the SA-2 tamed them beautifully and led to a smoother richer VO.
To view the SA-2 as a de-esser is to slightly miss the point in my book. It can de-ess to a degree, but it is not a broadband de-esser, in that it does not kill the HF and suck the life out of the dialogue (like the Avid and Waves de-essers seemed to be skilled at). Nor is it a surgical tool as indeed some de-essers, such as the Sonnox Supressor can be. A de-esser is a tool that is designed to achieve a certain job, getting rid of S’s,. The SA-2 is designed to improve the overall sound of recorded speech, and is a broad stroke tool for evening out the HMF and HF of dialogue. To my mind it perfectly suits being a “buss tamer”. It achieves this job that would otherwise require quite a few de-essers very carefully set indeed.
The SA-2 is not just for dialog. It’s equally useful for sung vocals, and is a great tool for adjusting the timbre of any track, I have also had success using it on my foley buss to tame spiky presence peaks, where the foley is not as ambient as I would like and it doesn’t have a room acoustic to “smooth the frequency response in the time domain”.
I always mix without the SA-2 in place (as I do indeed without bus compression and/or limiting), just using gentle source channel soft knee compression and gentle channel de-essing. For de-essing I mostly start with the SPL, but sometimes the Sonnox or the Fabfilter, depending on the source. I add the SA-2 on the dialogue group at the final stage as part a ‘dialogue mastering process’ before my bus-mastering compressor (I take the music mixer approach of ‘a little and often’). It seems to make eminent sense that way indeed and leads to better sounding dialogue.
The only change I would make to this plug-in would be to have a link control for the thresholds of the bands to quickly dial in the right level. Adjusting all the bands individually is a bit slower.
I first looked at this plug-in with a slightly cynical and marginally suspicious outlook as I am not at all a fan of “signature plug-ins”, but came away loving it and it is now a template stalwart. I have been living with the SA-2 now for over two years and it is, like my Dear DNS One, one of the plug-ins that you would have to wrench from my cold dead hands. It is simple, but highly effective. What is not to like?
Many of my discerning peers and friends, like mixers Pete Gates and John York use this plug-in. It is used on Game on Thrones by award winning Re-Recording Mixer Onnalee Blank, as I discovered in my interview for Resolution magazine – high praise indeed!
My dialogue is “Minklerized” to the best of my ability – what about yours? This is one to add to your ‘must have’ list. Not negotiable! Good work McDSP! You really deserved your Engineering Emmy for this.
You can pick up the SA-2 from ESV by following this link where you’ll also find the entire McDSP range of plug-ins




{kind=link}